









- はじめに
- 問38 顧客データフレーム(df_customer)とレシート明細データフレーム(df_receipt)から、各顧客ごとの売上金額合計を求めよ。ただし、売上実績がない顧客については売上金額を0として表示させること。また、顧客は性別コード(gender_cd)が女性(1)であるものを対象とし、非会員(顧客IDが”Z”から始まるもの)は除外すること。なお、結果は10件だけ表示させれば良い。
- 問39 レシート明細データフレーム(df_receipt)から売上日数の多い顧客の上位20件と、売上金額合計の多い顧客の上位20件を抽出し、完全外部結合せよ。ただし、非会員(顧客IDが”Z”から始まるもの)は除外すること。
- Pythonのコードやライブラリーについて知りたい場合
- 独学でデータ分析をしている方へ
はじめに
問38~問39のコードの説明を初心者や初学者でもわかるような方法でまとめました。
データサイエンス100本ノックのはじめ方は、以下のブログ記事を参考にしてください。
>>【Google Colabはじめ方】データサイエンス100本ノックーデータサイエンティスト協会
問38 顧客データフレーム(df_customer)とレシート明細データフレーム(df_receipt)から、各顧客ごとの売上金額合計を求めよ。ただし、売上実績がない顧客については売上金額を0として表示させること。また、顧客は性別コード(gender_cd)が女性(1)であるものを対象とし、非会員(顧客IDが”Z”から始まるもの)は除外すること。なお、結果は10件だけ表示させれば良い。
このあたりからやることが増えてきて難しくなってきす。
①まず、「各顧客ごとの売上金額合計」を求めます。
売上であるamountはdf_receiptにありますので、これを各顧客を表すcustomer_idごとに合計を求めます。合計をもとめるにはsum()、そして、インデックスが消えないように、最後に.reset_index()を使用します。
#各顧客ごとの売上金額合計
df_amount_sum = df_receipt.groupby('customer_id').amount.sum().reset_index()
②次に、顧客データフレーム(df_customer)から「性別コード(gender_cd)が女性(1)であるものを対象とし、非会員(顧客IDが”Z”から始まるもの)は除外」したものを抽出したデータフレームを作りましょう。
抽出には、query()を使用します。
「性別コード(gender_cd)が女性(1)であるもの」は問4と同じように一致を表す==を使用します。なお、gender_cdはint型です。
そして、「非会員(顧客IDが”Z”から始まるもの)は除外」は問34、問35と同様に、‘not customer_id.str.startswith(“Z”)’, engine=’python’とし、これを&で結びます(なお、andにしてもコードは通ります)。
#性別コード(gender_cd)が女性(1)で非会員(顧客IDが"Z"から始まるもの)を除外
df_tmp = df_customer.query('gender_cd ==1 & not customer_id.str.startswith("Z")',engine='python')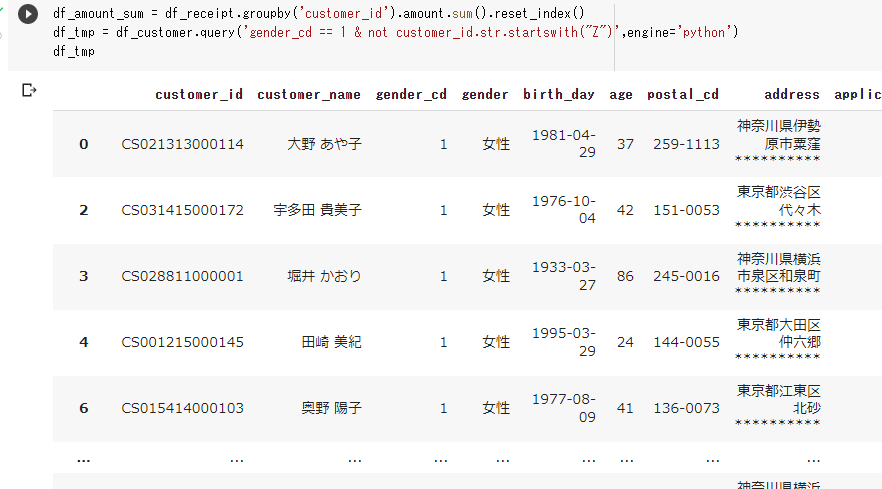
最後に、①、②をmergeして、「売上実績がない顧客については売上金額を0」として10件表示します。
mergeの仕方ですが、①、②の共通カラムcustomer_idを軸に、amountのカラムを左外部結合します。左外部結合するには、how=’left’とします。
また、「売上実績がない顧客については売上金額を0」にするには、欠損値を他の値に置換(穴埋め)するfillna()を使いますので、fillna(0)とします。
#結合して売上実績がない顧客について売上金額を0として表示
pd.merge(df_tmp['customer_id'],df_amount_sum,how='left',on='customer_id').fillna(0).head(10)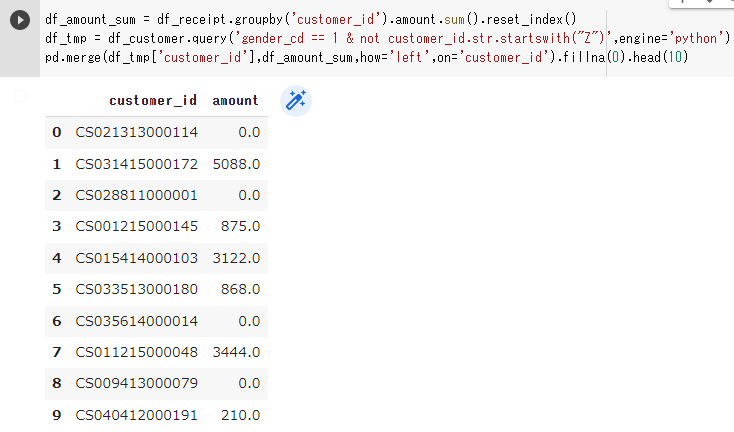
なお、今回は欠損値の穴埋めを行い、10件表示するだけなので、ここで終わりですが、fillna()の結果をもとのデータフレームに適用するには、inplace=Trueを入力する必要があります。
問39 レシート明細データフレーム(df_receipt)から売上日数の多い顧客の上位20件と、売上金額合計の多い顧客の上位20件を抽出し、完全外部結合せよ。ただし、非会員(顧客IDが”Z”から始まるもの)は除外すること。
① 売上金額合計の多い顧客の上位20件
直近の問題の処理と似ているので、「非会員(顧客IDが”Z”から始まるもの)は除外」した「売上金額合計の多い顧客の上位20件」を抽出したデータフレームを作りましょう。
売上金額合計については、sum()を使用し、これを‘customer_id’ごとに抽出します。
df_sum = df_receipt.groupby('customer_id').amount.sum().reset_index()次に、非会員(顧客IDが”Z”から始まるもの)の除外には、query()を使用します。
これは、問38でも使用した処理ですね。
df_sum = df_sum.query('not customer_id.str.startswith("Z")',engine='python')最後に、「売上金額合計の多い顧客」順に並び替えるため、sort_values()を使用し、20件格納します。
df_sum = df_sum.sort_values('amount',ascending=False).head(20)
② 売上日数の多い顧客の上位20件
「非会員(顧客IDが”Z”から始まるもの)は除外」した「売上日数の多い顧客の上位20件」を抽出したデータフレームを作成します。
df_receiptのcustomer_id CS006214000001の人をみてみると同じ日付で複数のものがあります。

問題文の指示どおり売上日数で抽出するには、同じ日付で複数のものを1回にしなければいけません。
つまり、重複していないデータのみを抽出したデータフレームを作成する必要があります。
これには、重複した行を抽出するduplicated()を使用し、subsetを用いて重複を判定する列を指定した上で、頭に論理否定演算子である~を使用することで、重複していないデータのみを抽出します。
df_sales_ymd = df_receipt[~df_receipt.duplicated(subset=['customer_id','sales_ymd'])]次に、売上日数をカウントするので、count()を使用します。
df_sales_ymd = df_sales_ymd.groupby('customer_id').sales_ymd.count().reset_index()そして、(顧客IDが”Z”から始まるもの)を除外し、売上日数の多い顧客の上位20件を抽出します。
df_sales_ymd = df_sales_ymd.query('not customer_id.str.startswith("Z")', engine='python')
df_sales_ymd = df_sales_ymd.sort_values('sales_ymd',ascending=False).head(20)最後に、①と②を外部結合します。外部結合は、how=’outer’とします。
pd.merge(df_sum,df_sales_ymd,how='outer',on='customer_id')
*結果が長いので10件以降は省略
Pythonのコードやライブラリーについて知りたい場合
Pythonはデータ分析でよく使われている言語です。
この機会にPythonのコードの打ち方・ライブラリーについてもっと知りたいと思った方は、以下のブログ記事をご覧ください。
データ分析入門・データサイエンス初心者・初学者向けにデータ分析でよく使うPythonをまとめました。
>>【データ分析初心者】Python構文~if文、format記法とf文字列~
>>【データ分析初心者】Python構文~for文、range関数、zip関数、enumerate関数~
>>【データ分析初心者】Python構文~無名関数lambda式、内包表記、map関数~
>>【データ分析初心者】Pandas~loc[]、iloc[]、スライス、drop()、isin()~
>>【データ分析初心者】Matplotlib、Seabornーscatter、hist、countplot 、barplot
独学でデータ分析をしている方へ
機械学習やデータサイエンス・データ分析を独学で学ぶには、どうしたらよいかをまとめてみましたので、興味がある方はこちらのブログ記事をご覧ください。