









はじめに
データ分析・データサイエンスの初心者・初学者に最初に覚えて欲しいPythonのライブラリがいくつかあります。
今回はその中の一つである、データ分析でよく使うMatplotlib、Seabornを紹介します。
このブログでは、①基本をしっかりと示し、②実際のデータ分析でどのように使われるかという具体例を紹介します!
読み終えたあとには、しっかりとその構文が身についていると思います。
それではさっそく、Google Colaboratoryをつかって動かしてみましょう。
Google Colaboratoryについては知りたい方は、以下のブログ記事を参考にしてください。
>>Google Colaboratoryとは? いつできた? mount、ファイルの読み込み等の使い方
>>Google Colaboratoryよく使う便利なショートカットキー
Matplotlib、Seabornとは
Matplotlibは、Pythonで静的、アニメーション、インタラクティブな視覚化を作成するための包括的なライブラリです。また、SeabornはmatplotlibをベースにしたPythonのデータ可視化ライブラリです。
自分がデータ分析をする際や、その分析結果を誰かに発表するときに、図表にして説明するほうがわかりやすいですよね。データを視覚的にわかりやすくするために用いるのがMatplotlibやSeabornです。
さっそく、データサイエンス100本ノック(構造化データ加工編)のデータセットを用いてMatplotlibやSeaborn使用してみましょう。
データサイエンス100本ノック(構造化データ加工編)を知りたい方は下記のブログ記事を参考にしてください。
>>【Google Colabはじめ方】データサイエンス100本ノックーデータサイエンティスト協会
Matplotlib 折れ線グラフplot()
日付ごとの売上のような時系列のデータを可視化するときに用いる折れ線グラフを表示してみたいと思います。
df_receiptを用いて折れ線グラフを見てみましょう。
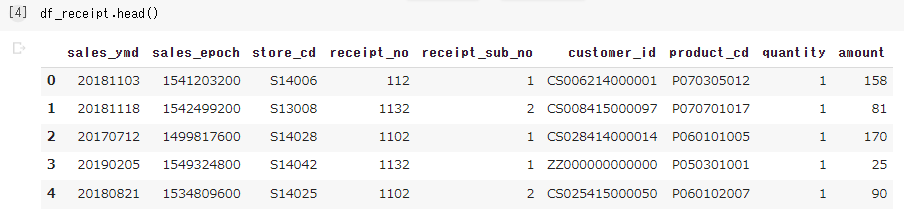
ここで、‘sales_ymd’と‘amount’を折れ線グラフで表してみます。
‘sales_ymd‘は日付、‘amount’は売上です。
しかし、df_receiptをみてみると、‘sales_ymd’が日付順になっていませんし、同じ日付で別のデータもあります(商品ごとのレシートのため)。
まず、前処理として、‘sales_ymd’を日付順にして、その日付ごとの売上合計額のデータを作成します。
df_receipt[['sales_ymd','amount']].groupby('sales_ymd').sum().reset_index()こちらのコードはdf_receiptから’sales_ymd’,’amount’を抜き出して、’sales_ymd’の合計値ごとに表示したうえで、インデックスを振りなおしたコードです。こちらを表示しみます。
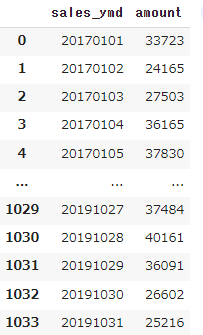
df_receipt_1 = df_receipt[['sales_ymd','amount']].groupby('sales_ymd').sum().reset_index()これをdf_receipt_1に格納した上で、折れ線グラフで確認してみましょう。
折れ線グラフを描くには、plot(x,y)を用います。
引数xyには、それぞれ、x軸、y軸に表示したいものを入れます。
今回は、x軸に日付、y軸に売上の合計を表してみます。
import matplotlib.pyplot as plt
x = df_receipt_1['sales_ymd']
y = df_receipt_1['amount']
plt.plot(x,y)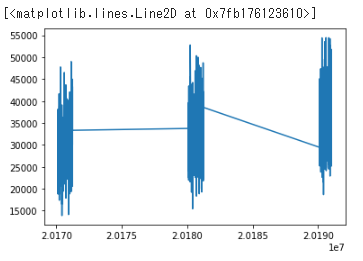
わけがわからない図が表示されました。
これは、’sales_ymd’の型がint型(整数)だったため、このように表示されてしまいました。
これを時系列の折れ線グラフとして表示するためには、‘sales_ymd’の型を日付型にする必要があります。
from datetime import datetime, date
df_receipt_1['sales_ymd_date'] = pd.to_datetime(df_receipt_1['sales_ymd'],format='%Y%m%d')これで再度表示してみます。
x = df_receipt_1['sales_ymd_date']
y = df_receipt_1['amount']
plt.plot(x,y)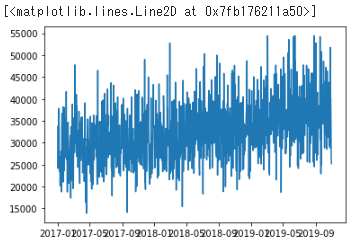
図を表示する部分が小さいので、ごちゃごちゃしてますので、サイズを大きくしてみます。plt.figure(figsize=())を使用します。
plt.figure(figsize=(20,8))
x = df_receipt_1['sales_ymd_date']
y = df_receipt_1['amount']
plt.plot(x,y)
Matplotlib 散布図scatter()
散布図とは、2つの組み合わせたデータに対して、x軸、y軸上に点で表示します。
df_productを用いて散布図を見てみましょう。

ここで、‘unit_price’と‘unit_cost’を散布図で表してみます。
‘unit_price’=製品価格は、当然、‘unit_cost’=製品コストをもとに算出されていると思われます。
それを散布図で確認してみましょう。
散布図を描くには、plt.scatter(x, y)を用います。
引数xyには、それぞれ、x軸、y軸に表示したいものを入れます。
import matplotlib.pyplot as plt
x = df_product['unit_price']
y = df_product['unit_cost']
plt.scatter(x, y)
*注 <matplotlib.collections.PathCollection at 0x7f88b55f8290>を消したい場合には、;を打ち込むと表示されません。

きれいに線形関係がありますね。ちゃんと‘unit_price’=製品価格は、‘unit_cost’=製品コストをもとに算出されていることが確認できました。
Matplotlib ヒストグラム hist()
ヒストグラムとは、それぞれの値の度数(値が出現する回数)を示すものです。データの全体象を把握したいときに用います。
今度はdf_customerのageを用いてヒストグラムを見てみましょう。どの年齢が一番多いでしょうか?

ヒストグラムを描くには、plt.hist(x)を用います。引数xには、表示したいものを入れます。
import matplotlib.pyplot as plt
x = df_customer['age']
plt.hist(x);

ヒストグラムで表示することで、df_customerには、40代から50代の方が多いことがわかります。
Seaborn countplot()
Seabornのcountplotを用いるとデータの件数を集計し、それをヒストグラムとして表示してくれます。
df_customerのgenderを用いて見てましょう。どの性別がどれくらいいるでしょうか。
countplotを用いるには、countplot()で引数xには集計対象の列名を入れ、dataには、対象のデータを入れましょう。
import seaborn as sns
sns.countplot(x='gender',data=df_customer);
genderの部分の日本語が文字化けしてしまってますね。このようにMatplotlib、Seabornでは、日本語が文字化けしてしまいます。
Matplotlib、Seaborn 文字化け対処(日本語表示)
Matplotlibの日本語を!PIPでjapanize-matplotlibインストールしてから、japanize_matplotlibをインポートすると文字化けが解消できます。
!pip install japanize-matplotlib
import japanize_matplotlib
import seaborn as sns
sns.countplot(x='gender',data=df_customer);
これで、日本語が表示されました。女性が一番多いことも確認できました。
countplotの引数にhueを用いると、各軸をさらに分割して集計することができます。
例えば、年代ごとにgenderを集計してみましょう!
まず、df_customerには、age=年齢はありますが、年代がありません。そこで、年代=eraを作成します。
df_customer_1 = df_customer
df_customer_1['era'] = df_customer_1['age'].apply(lambda x: math.floor(x/10)*10)
df_customer_1
一番右側に年代(era)ができました。
年代の作り方の詳細な解説が知りたい方は、以下のブログ記事を参考にしてください。
>>【問42~問44】データサイエンス100本ノック 解説
それでは、df_customer_1を用いて、年代ごとに性別を見てましょう。
import seaborn as sns
sns.countplot(x='era',hue='gender',data=df_customer_1);

このように2軸で表示できます!
Seaborn barplot()
Seabornのbarplotを用いるとデータの平均値と95%信頼区間を表示してくれます。
今回は、df_productを用います。

df_productにあるcategory_major_cdのunit_priceを見てましょう。
barplot()の引数には、xとyにそれぞれ表示させたいものの列を入力し、dataにそのデータセットを記入します。今回は、x軸にcategory_major_cdを表示し、y軸にunit_price、データセットはdf_productなので、以下のようにコードを打ちます。
import seaborn as sns
sns.barplot(x="category_major_cd", y="unit_price", data=df_product);

barplotの見方ですが、平均値と95%信頼区間(黒いエラーバー)が表示されるので、例えば、一番左のcategory_major_cdの4を見てみると、4のunit_priceの平均は400弱で(青色のバー)、df_productのデータ中category_major_cdの4は95%が300~500のunit_priceということ表しています(黒いエラーバー)。
今回、category_major_cdはラベルは一つの数字ですし、ラベル数も少ないので、横のラベルと重なることはありませんが、例えば、category_medium_cdを同じように表示した場合、重なってどれが何を表しているのかわからなくなります。

このとき、category_medium_cdつまりx軸のラベル表示を90度回転させれば、それを解決できます。
しかし、seabornでは、ラベルの回転のメソッドがありません。そこで、このような場合には、matplotlibを用います。
matplotlibで図表の設定をしながら、seabornのbarplot()でその中身を表示させる方法です。
まず、matplotlibで表示させる図表のサイズを確定します。上記の図表では横幅が小さかったので、横幅を少し大きくしましょう。plt.figure()の引数figsize=()で図表の大きさを指定できます。
plt.figure(figsize = (20,8))次に、seabornのbarplot()を用いて、先ほどと同じ引数を入れ、これをaxに格納します。
そして、set_xticklabels() を使用して、ラベルを回転させます。今回は90度回転させたいので、90を入れます。
ax.set_xticklabels(ax.get_xticklabels(),rotation = 90)
x軸のラベルが90度回転したので、重ならなくなりました!
データ分析入門・データサイエンス初心者・初学者向けにデータ分析でよく使うPythonをまとめました。
>>【データ分析初心者】Python構文~if文、format記法とf文字列~
>>【データ分析初心者】Python構文~for文、range関数、zip関数、enumerate関数~
>>【データ分析初心者】Python構文~無名関数lambda式、内包表記、map関数~
>>【データ分析初心者】Pandas~loc[]、iloc[]、スライス、drop()、isin()、info()とastype()
>>【データ分析初心者】Pythonを使って、和暦から西暦への変換を行う
書籍や動画でデータ分析を学びたい方へ
機械学習やデータサイエンスを独学で学びたい方のために、ブログ記事をまとめてみました。
書籍、動画などなど、厳選したオススメの方法をまとめています。
興味がある方はご覧ください。
