









はじめに
Kaggleは、英語のページしかありません。そこで、日本語で読みたい方向けに記事を作成しました。
Kaggle入門コンペであるHouse Pricesの概要やEDAが済みました。
次は、ランダムフォレストモデル(RandomForestRegressor)を適用して、submissionファイルを提出してみましょう!
Google Colaboratoryについては知りたい方は、以下のブログ記事を参考にしてください。
>>Google Colaboratoryとは? いつできた? mount、ファイルの読み込み等の使い方
>>Google Colaboratoryよく使う便利なショートカットキー
準備
Pandasをインポートします。
import pandas as pd次に、ドライブをマウントして、train.csvを読み込んでください。
注意:‘/kaggle/House Prices/←の部分はフォルダ構成によって異なるので注意してください。
df_train = pd.read_csv('/kaggle/House Prices/train.csv')カテゴリ変数の処理
df_trainのカラムのデータには、文字列で表されているもの、つまり数値化されていないカラムのデータがあります。

このような数値化されていないカテゴリ変数について、何も処理をせずにすると多くの機械学習モデルは使用することはできません。
つまり、機械学習モデルを適用するために、変数を数値化する必要があります!
これをダミー変数化といいます。ダミー変数化は簡単です。get_dummies()で行うことができます。
df_train = pd.get_dummies(df_train)
これでカテゴリ変数を数値化できました。
モデルの作成ーランダムフォレスト
それでは、モデルを作成していきます。今回はランダムフォレストを使用します。
ランダムフォレストとは、決定木(DecisionTree)を複数作成することで予測を行うモデルです。
データセットの様々なサンプルに多数の決定木を当てはめ、予測精度を向上させオーバーフィッティング(過学習)を抑制するために平均化を使用して予測を行います。
scikit-learnのsklearn.ensembleにRandomForestRegressorがありますので、こちらを使用します。
from sklearn.ensemble import RandomForestRegressor今回の目的変数(予測値)は、SalePriceです。
まずは、目的変数(予測値)として、train_yを作成します。
そして、モデルに使用する特徴量は、前回のEDAでみたように目的変数との関連性が深い、’OverallQual’, ‘GrLivArea’, ‘GarageCars’, ‘TotalBsmtSF’, ‘FullBath’, ‘YearBuilt’を使用し、これをtrain_Xに格納します。
train_y = df_train.SalePrice
predictor_cols = ['OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']
train_X = df_train[predictor_cols]前回のEDAはこちらのブログ記事を参考にしてください。
>>【kaggle入門ー重回帰分析】House Prices – Advanced Regression TechniquesーEDA
モデルを学習させます。
my_model = RandomForestRegressor()
my_model.fit(train_X, train_y)
モデルをテストデータに適用する
テストデータを読み込んで、これをdf_testとします。そして、train_Xと同じ特徴量を抽出し、これをtest_Xに格納します。
注意:‘/kaggle/House Prices/test.csv←の部分はフォルダ構成によって異なるので注意してください。
df_test = pd.read_csv('/content/drive/MyDrive/kaggle/House Prices/test.csv')
test_X = df_test[predictor_cols]test_Xには、欠損値があります。
欠損値があるとモデルが適用できず、実行時にエラーとなってしまうことがあります。
そこで、欠損値を埋めましょう。
欠損値の埋め方は様々ありますが、今回は0で埋めますので、fillna(0)としinplace=Trueでもとのデータに適用させます。
最後に、欠損値がなくなったこともしっかりと確認しましょう。
test_X.fillna(0,inplace=True)
test_X.isnull().sum()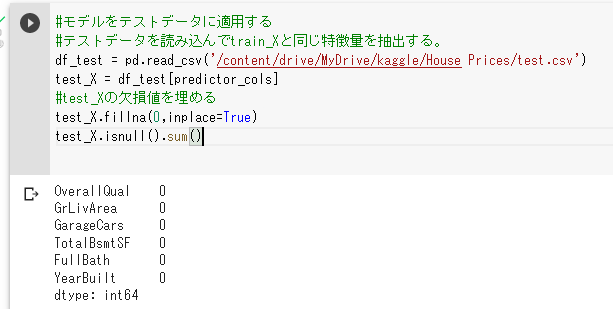
住宅の予想価格をモデルを使って、pred_pricesに格納し、これを表示します。
pred_prices = my_model.predict(test_X)
print(pred_prices)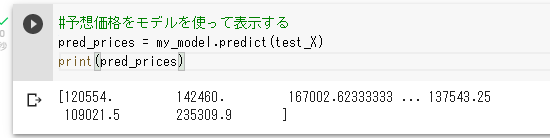
ファイルの提出
最後にファイルを提出します。提出ファイルの形式は、以下のもので指定されています。

そのため、Idには、df_testのIdを、SalePriceには、住宅の予想価格が格納されたpred_pricesを使用します。
また、indexがないものを求められているので、csvにする際には、index=Falseとします。
my_submission = pd.DataFrame({'Id': df_test.Id, 'SalePrice': pred_prices})
my_submission.to_csv('submission.csv', index=False)上記コードを打ち、Google Colabの左側のファイル(赤い囲みの部分)をクリックすると、下記のように表示されます。
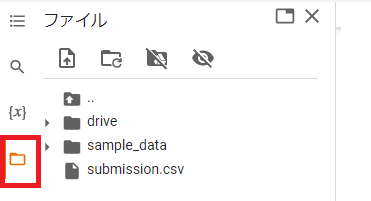
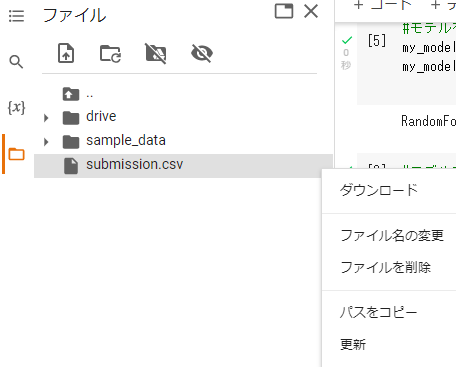
submission.csvにカーソルを合わせ、縦に並んだ…を押すと下記のようになりますので、これをダウンロードしてください。
ダウンロード後、KaggleのSubmit Predicitionsを押すと、下記のようになりますので、step1のところにドラッグアンドドロップでファイルをアップロードしてください。
アップロード後、画面をスクロールするとMake Submissionをクリックするとファイルを提出できます。
Kaggleで悩んだら
「Kaggle で勝つデータ分析の技術」
以下の書籍は、Kaggleを始める方には本当にオススメの書籍です。Kaggleでわからないことや悩んだことがあった方は、購入を検討してみください。
本だけでは物足りないという方は、動画のプラットフォームで学ぶこともオススメです。興味がございましたら、以下の無料のオンライン説明会に参加してみてはいかがでしょうか。
