









はじめに
Kaggleは、英語のページしかありません。そこで、日本語で読みたい方向けに記事を作成しました。
Kaggle入門として、House Pricesのコンペで、lightgbmを適用して、submissionファイルを提出してみましょう!
Google Colaboratoryについては知りたい方は、以下のブログ記事を参考にしてください。
>>Google Colaboratoryとは? いつできた? mount、ファイルの読み込み等の使い方
>>Google Colaboratoryよく使う便利なショートカットキー
準備
Pandasをインポートします。
import pandas as pd次に、ドライブをマウントして、train.csvを読み込んでください。
注意:‘/kaggle/House Prices/←の部分はフォルダ構成によって異なるので注意してください。
また、目的変数や特徴量もここで作成しておきましょう。
今回の目的変数(予測値)は、SalePriceです。これをtrain_yに格納します。
そして、モデルに使用する特徴量は、EDAでみたように目的変数との関連性が深い、‘OverallQual’, ‘GrLivArea’, ‘GarageCars’, ‘TotalBsmtSF’, ‘FullBath’, ‘YearBuilt’を使用し、これをtrain_Xに格納します。
なお、前回のEDAはこちらのブログ記事を参考にしてください。
>>【kaggle入門ー重回帰分析】House Prices – Advanced Regression TechniquesーEDA
df_train = pd.read_csv('/kaggle/House Prices/train.csv')
train_y = df_train.SalePrice
predictor_cols = ['OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']
train_x = df_train[predictor_cols]ホールドアウト法
今回は、モデルの精度をさらに高めるために、ホールドアウト法を使用します。
ホールドアウト法とは、データを学習データとテストデータにランダムに2分割し、学習データでモデルを構築し、テストデータでモデルを検証する手法です。
これを行う目的は、汎化性能(未知の新たなデータに予測できる性能)を高くすることです。
今回用いるのは、データを学習用と検証用に交差させる検証法であるクロスバリデーションのうち、KFoldを用います。
KFoldは、scikit-learnのsklearn.model_selectionにKFoldがありますので、こちらを使用します。
KFoldは、データをk個にランダムに分割してくれます(K-Folds cross-validator)。
今回は学習データ2つとテストデータ2つの合計4つ(tr_x,va_x、tr_y,va_y)に分割します。
from sklearn.model_selection import KFold
kf = KFold(n_splits=4,shuffle=True,random_state=71)
tr_idx,va_idx = list(kf.split(train_x))[0]
tr_x,va_x = train_x.iloc[tr_idx],train_x.iloc[va_idx]
tr_y,va_y = train_y.iloc[tr_idx],train_y.iloc[va_idx]モデルの使用
今回は、lightgbmを使用します。
lightgbmは、ツリーベースの学習アルゴリズムを用いた勾配ブースティング手法です。
トレーニング速度の高速化と高効率化、メモリ使用量の削減、精度の向上、並列・分散・GPU学習への対応、大規模データの取り扱いが可能という利点があります。
#ligthgbmを使用します。
import lightgbm as lgb
lgb_train = lgb.Dataset(tr_x,tr_y)
lgb_test = lgb.Dataset(va_x,va_y)
params = {'metric' : 'rmse'}
num_round = 100
#特徴量はパラメータで指定
categorical_features = ['OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']
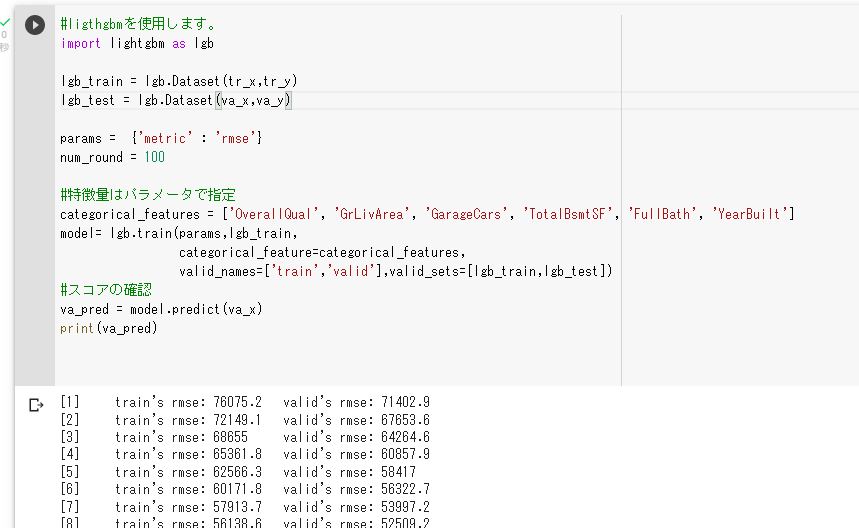
model= lgb.train(params,lgb_train,
categorical_feature=categorical_features,
valid_names=['train','valid'],valid_sets=[lgb_train,lgb_test])
#スコアの確認
va_pred = model.predict(va_x)
print(va_pred)
モデルの適用し、ファイルを提出する
#モデルをテストデータに適用する
#テストデータを読み込んでtrain_Xと同じ特徴量を抽出する。
df_test = pd.read_csv('/content/drive/MyDrive/kaggle/House Prices/test.csv')
test_X = df_test[predictor_cols]#予想価格をモデルを使って表示する
pred_prices = model.predict(test_X)
print(pred_prices)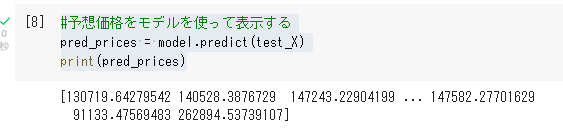
#提出ファイルを作成
my_submission = pd.DataFrame({'Id': df_test.Id, 'SalePrice': pred_prices})
my_submission.to_csv('submission2.csv', index=False)モデルの適用からファイルの提出までの方法を詳しく知りたい方は以下のブログ記事を参考にしてください。
>>【kaggle入門ー重回帰分析】House Prices – Advanced Regression Techniquesーランダムフォレスト
Kaggleで悩んだら
「Kaggle で勝つデータ分析の技術」
以下の書籍は、Kaggleを始める方には本当にオススメの書籍です。Kaggleでわからないことや悩んだことがあった方は、購入を検討してみください。
本だけでは物足りないという方は、動画のプラットフォームで学ぶこともオススメです。興味がございましたら、以下の無料のオンライン説明会に参加してみてはいかがでしょうか。