









- はじめに
- 問32 レシート明細データフレーム(df_receipt)の売上金額(amount)について、25%刻みでパーセンタイル値を求めよ。
- 問33 レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、330以上のものを抽出せよ。
- 問34 レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求めよ。ただし、顧客IDが”Z”から始まるのものは非会員を表すため、除外して計算すること。
- Pythonのコードやライブラリーについて知りたい場合
- 独学でデータ分析をしている方へ
はじめに
問32~問34のコードの説明を初心者や初学者でもわかるような方法でまとめました。
データサイエンス100本ノックのはじめ方は、以下のブログ記事を参考にしてください。
>>【Google Colabはじめ方】データサイエンス100本ノックーデータサイエンティスト協会
問32 レシート明細データフレーム(df_receipt)の売上金額(amount)について、25%刻みでパーセンタイル値を求めよ。
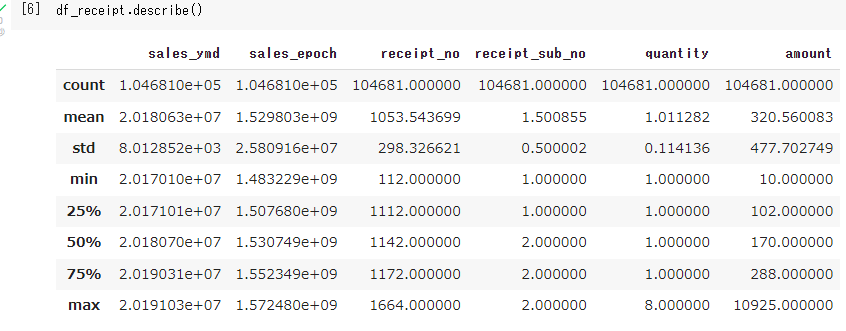
データ数を区切る値をパーセンタイル値といいます。よって、25%刻みのパーセンタイル値は、25,50、75、100になります。
パーセンタイル値を求めるには、np.percentile()を使用します。
np.percentile(df_receipt['amount'],q=[25,50,75,100])
別の方法はもっと簡単です。describe()を使用すると、各カラムのカウント数、平均、標準偏差、最大値、最小値、パーセンタイル値を取得できます。
これは、実務上もよく使うので覚えておいてください。
問33 レシート明細データフレーム(df_receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の平均を計算し、330以上のものを抽出せよ。
問27と処理が似ています。
まず、「(df_receipt)に対し、店舗コード(store_cd)ごとに」表示する必要があるので、groupby()を使用します。
売上金額(amount)の平均を計算するので、agg({‘カラム名’: ‘mean’})を使用し、インデックスが消えないように、.reset_index()を用います。
それを、「330以上のものを抽出」するので、query()を使用します。
df_receipt.groupby('store_cd').agg({'amount':'mean'}).reset_index().query('amount >= 330')
なお、以下のコードでも同じ結果がでます。
df_receipt.groupby('store_cd').amount.mean().reset_index().query('amount>=330')問34 レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求めよ。ただし、顧客IDが”Z”から始まるのものは非会員を表すため、除外して計算すること。
(df_receipt)の顧客IDが“Z”から始まるのものは非会員を表すため、除外する必要があります。
これは問10で使用した処理と同じように、“Z”から始まるもののみを除外して抽出すればいいので、query()を使用し、文字列の前方一致のstr.startswith(“文字列”)を使います。
なお、文字列の中でシングルクォーテーションを使う場合はダブルクォーテーションで囲んでください。一方、ダブルクォーテーションを使う場合はシングルクォーテーションで囲むというのを忘れないでください。
そして、.query( )で文字列メソッドを使う場合、第2引数に「engine=’python’」を指定しないとエラーがでます!
よって、.query(‘not customer_id.str.startswith(“Z”)’, engine=’python’)
となります。
また、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求める必要があります。
これには、customer_idをグルーピングし、amountの合計は、sum()を使って計算します。さらに、その合計を、mean()を用いて全顧客の平均を求めます。
まとめると、.groupby(‘customer_id’).amount.sum().mean()になります。
df_receipt.query('not customer_id.str.startswith("Z")', engine='python').groupby('customer_id').amount.sum().mean()
Pythonのコードやライブラリーについて知りたい場合
Pythonはデータ分析でよく使われている言語です。
この機会にPythonのコードの打ち方・ライブラリーについてもっと知りたいと思った方は、以下のブログ記事をご覧ください。
データ分析入門・データサイエンス初心者・初学者向けにデータ分析でよく使うPythonをまとめました。
>>【データ分析初心者】Python構文~if文、format記法とf文字列~
>>【データ分析初心者】Python構文~for文、range関数、zip関数、enumerate関数~
>>【データ分析初心者】Python構文~無名関数lambda式、内包表記、map関数~
>>【データ分析初心者】Pandas~loc[]、iloc[]、スライス、drop()、isin()~
>>【データ分析初心者】Matplotlib、Seabornーscatter、hist、countplot 、barplot
独学でデータ分析をしている方へ
機械学習やデータサイエンス・データ分析を独学で学ぶには、どうしたらよいかをまとめてみましたので、興味がある方はこちらのブログ記事をご覧ください。