









- はじめに
- 問69 レシート明細データフレーム(df_receipt)と商品データフレーム(df_product)を結合し、顧客毎に全商品の売上金額合計と、カテゴリ大区分(category_major_cd)が”07″(瓶詰缶詰)の売上金額合計を計算の上、両者の比率を求めよ。抽出対象はカテゴリ大区分”07″(瓶詰缶詰)の売上実績がある顧客のみとし、結果は10件表示させればよい。
- 問70 レシート明細データフレーム(df_receipt)の売上日(sales_ymd)に対し、顧客データフレーム(df_customer)の会員申込日(application_date)からの経過日数を計算し、顧客ID(customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示させれば良い(なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。
- Pythonのコードやライブラリーについて知りたい場合
- 独学でデータ分析をしている方へ
はじめに
データサイエンス100本ノックのはじめ方は、以下のブログ記事を参考にしてください。
>>【Google Colabはじめ方】データサイエンス100本ノックーデータサイエンティスト協会
問69 レシート明細データフレーム(df_receipt)と商品データフレーム(df_product)を結合し、顧客毎に全商品の売上金額合計と、カテゴリ大区分(category_major_cd)が”07″(瓶詰缶詰)の売上金額合計を計算の上、両者の比率を求めよ。抽出対象はカテゴリ大区分”07″(瓶詰缶詰)の売上実績がある顧客のみとし、結果は10件表示させればよい。
まず、レシート明細データフレーム(df_receipt)と商品データフレーム(df_product)の共通カラムがあるか探します。
df_receipt_columns = df_receipt.columns
df_product_columns = df_product.columns
df_and = set(df_receipt_columns) & set(df_product_columns)
df_and
product_cdが共通しているため、pd.merge()を用いて内部結合し、customer_idごとに全商品の売上金額の合計を算出します。
それには、groupby()、amount.sum()を使用します。
df_tmp1 = pd.merge(df_receipt,df_product,how='inner',on='product_cd').groupby('customer_id').amount.sum().reset_index()
次に、「抽出対象はカテゴリ大区分”07″(瓶詰缶詰)の売上実績がある顧客のみ」なので、(df_product)からカテゴリ大区分(category_major_cd)が“07”(瓶詰缶詰)を抽出します。
ただし、category_major_cdのデータを見てみると0が付かないので単純にint型の7となっています。そのため、以下のコードにします。
df_product_7 = df_product.query('category_major_cd == 7')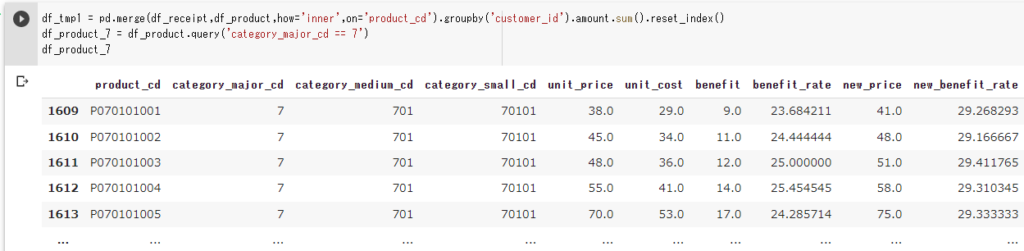
df_product_7とdf_tmp1を内部結合し、売上金額合計を計算します。
df_tmp2 = pd.merge(df_receipt,df_product_07,how='inner',on='product_cd').groupby('customer_id').amount.sum().reset_index()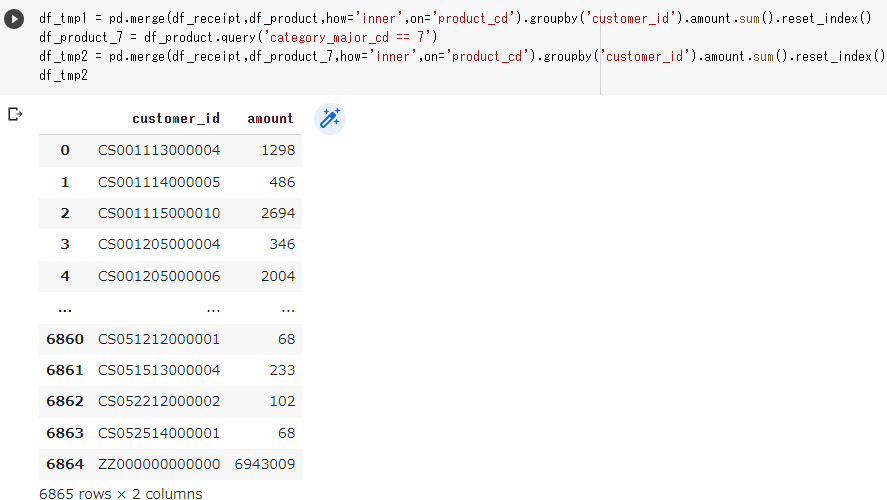
最後に、df_tmp1とdf_tmp2を結合し、その両者の比率を求めたものを作成します。
両社の比率は、瓶詰缶詰の売上金額合計/全商品の売上金額合計で計算できます。
df_tmp3 = pd.merge(df_tmp1,df_tmp2,how='inner',on='customer_id')
df_tmp3['rate_7'] = df_tmp3['amount_y'] / df_tmp3['amount_x']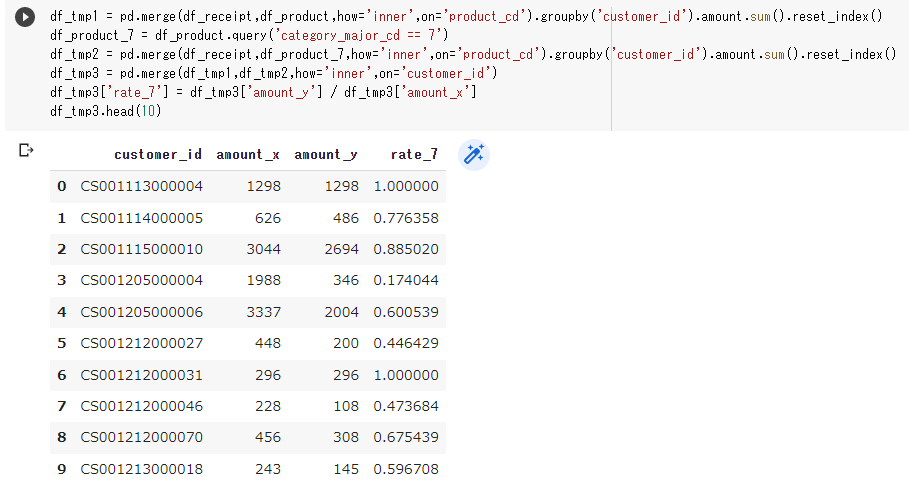
問70 レシート明細データフレーム(df_receipt)の売上日(sales_ymd)に対し、顧客データフレーム(df_customer)の会員申込日(application_date)からの経過日数を計算し、顧客ID(customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示させれば良い(なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。
レシート明細データフレーム(df_receipt)の売上日(sales_ymd)に対し、顧客データフレーム(df_customer)の会員申込日(application_date)からの経過日数を計算する必要があります。
まず、顧客ID(customer_id)、売上日(sales_ymd)、会員申込日(application_date)が抽出項目なので、(df_receipt)と(df_customer)を内部結合します。
df_tmp = pd.merge(df_receipt[['customer_id', 'sales_ymd']], df_customer[['customer_id', 'application_date']], how='inner', on='customer_id')
重複している行が確認できましたので、drop_duplicates()で、重複した行を削除します。
df_tmp = df_tmp.drop_duplicates()
次に、「sales_ymdは数値、application_dateは文字列でデータを保持している」ため、それらを用いて計算するためには、(application_date)と売上日(sales_ymd)をpd.to_datetimeで日付型に変換する必要があります。
変換方法の詳細は問46、問47を参考にしてください。
df_tmp['sales_ymd'] = pd.to_datetime(df_tmp['sales_ymd'],format='%Y%m%d')
df_tmp['application_date'] = pd.to_datetime(df_tmp['application_date'],format='%Y%m%d')
最後に、elapsed_dateのカラムを作成し、そこに、売上日(sales_ymd)から会員申込日(application_date)の差分である経過日数を計算します。
df_tmp['elased_date'] = df_tmp['sales_ymd']-df_tmp['application_date']
Pythonのコードやライブラリーについて知りたい場合
Pythonはデータ分析でよく使われている言語です。
この機会にPythonのコードの打ち方・ライブラリーについてもっと知りたいと思った方は、以下のブログ記事をご覧ください。
データ分析入門・データサイエンス初心者・初学者向けにデータ分析でよく使うPythonをまとめました。
>>【データ分析初心者】Python構文~if文、format記法とf文字列~
>>【データ分析初心者】Python構文~for文、range関数、zip関数、enumerate関数~
>>【データ分析初心者】Python構文~無名関数lambda式、内包表記、map関数~
>>【データ分析初心者】Pandas~loc[]、iloc[]、スライス、drop()、isin()~
>>【データ分析初心者】Matplotlib、Seabornーscatter、hist、countplot 、barplot
独学でデータ分析をしている方へ
機械学習やデータサイエンス・データ分析を独学で学ぶには、どうしたらよいかをまとめてみましたので、興味がある方はこちらのブログ記事をご覧ください。