









はじめに
Kaggleは、英語のページしかありません。そこで、日本語で読みたい方向けに記事を作成しました。
Kaggle入門のコンペであるHouse Pricesの概要の説明が済みました。
次に実際にGoogle Colabを動かして、与えられたデータに対してEDA(Explanatory Data Analysis:探索的データ分析)をしてみましょう!
Google Colaboratoryについては知りたい方は、以下のブログ記事を参考にしてください。
>>Google Colaboratoryとは? いつできた? mount、ファイルの読み込み等の使い方
>>Google Colaboratoryよく使う便利なショートカットキー
こちらの方のコードを参考にEDAについて解説していきます。
https://www.kaggle.com/pmarcelino/comprehensive-data-exploration-with-python
準備
必要なものをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy.stats import norm
from sklearn.preprocessing import StandardScaler
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline次に、ドライブをマウントして、train.csvを読み込んでください。
注意:‘/kaggle/House Prices/←の部分はフォルダ構成によって異なるので注意してください。
df_train = pd.read_csv('/kaggle/House Prices/train.csv')EDAーデータの中身を探索してみる
df_trainのカラムをみてみます。
df_train.columns
カラムの内容について詳しく知りたい方は、以下のブログ記事を参考にしてください。
>>House Prices – Advanced Regression Techniques
目的関数であるSalePriceの概要を把握します。
df_train['SalePrice'].describe()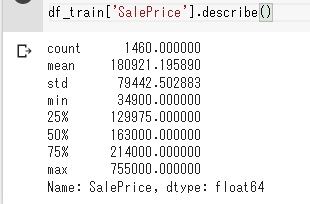
seabornを使って、SalePriceをみてみます。
sns.distplot(df_train['SalePrice']);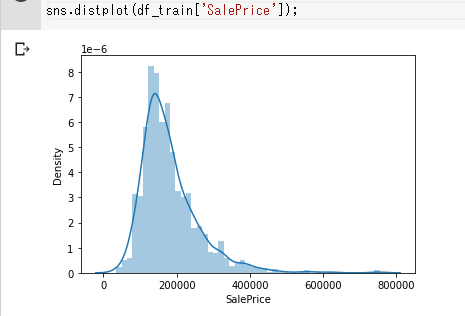
GrLivArea(リビングの広さ)とSalePriceの関係をplot.scatter()を用いて散布図でみてみます。
var = 'GrLivArea'
data = pd.concat([df_train['SalePrice'],df_train[var]],axis=1)
data.plot.scatter(x=var,y='SalePrice',ylim=(0,800000));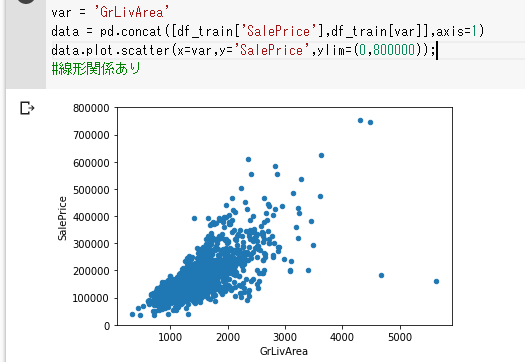
パッとみると線形関係がありそうです。
TotalBsmtSF(地下室面積)とSalePriceの関係をplot.scatter()散布図でみてみます。
var = 'TotalBsmtSF'
data = pd.concat([df_train['SalePrice'],df_train[var]],axis=1)
data.plot.scatter(x=var,y='SalePrice',ylim=(0,800000));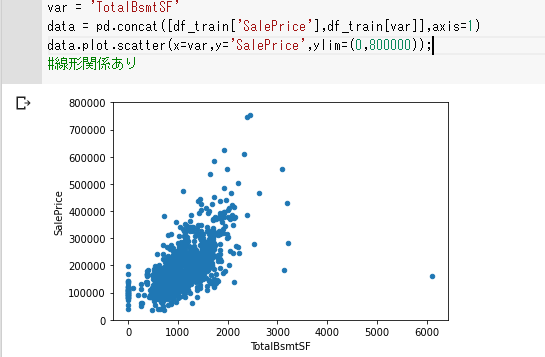
こちらも線形関係がありそうです。
OverallQual(全体的な素材と仕上げの品質)とSalePriceの関係をboxplot()をはこひげ図でみてみます。
var = 'OverallQual'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
fig, ax = plt.subplots(figsize=(8, 6))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000);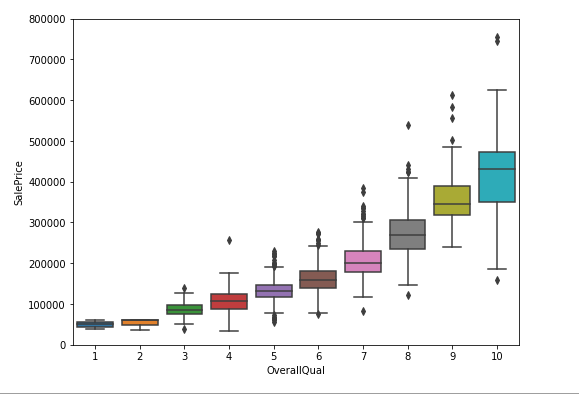
OverallQualとSalePriceには関係がありそうです。
今度は、YearBuilt(築年数)とSalePriceの関係をboxplot()をはこひげ図でみてみます。
var = 'YearBuilt'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
fig, ax = plt.subplots(figsize=(16, 8))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000);
plt.xticks(rotation=90);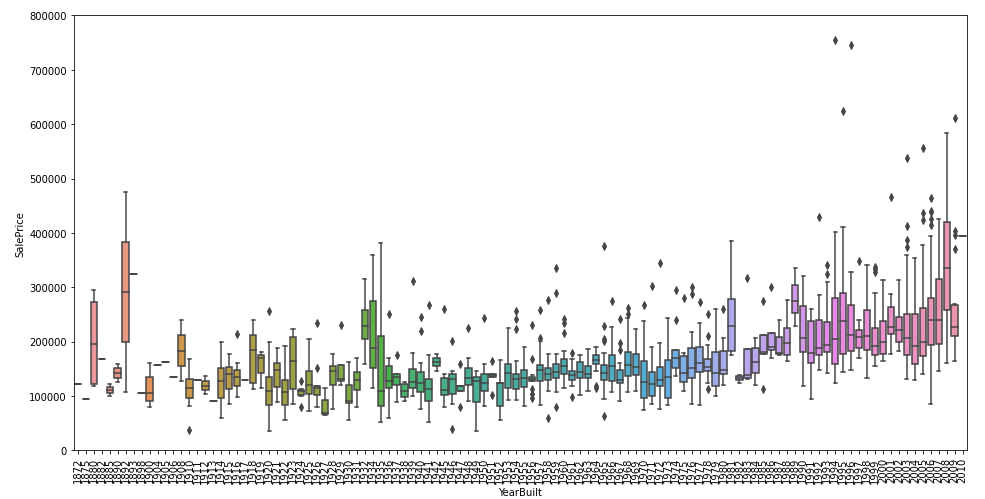
YearBuiltとSalePriceもおおむね関係ありそうです。
次は、カラム同士をヒートマップで関連性を見てみます。
corrmat = df_train.corr()
fig, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);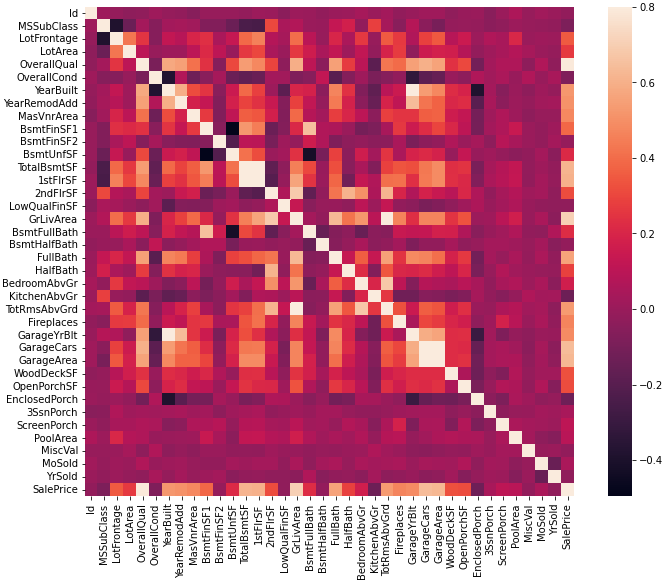
SalePriceには、いままで見たもの以外にも関係がありそうなものが複数ありそうです。
それでは、SalePriceの相関行列トップ10を見てみます。
k = 10
cols = corrmat.nlargest(k,'SalePrice')['SalePrice'].index
cm = np.corrcoef(df_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm,cbar=True,annot=True,square=True,fmt='.2f',annot_kws={'size':10},yticklabels=cols.values,xticklabels=cols.values)
plt.show()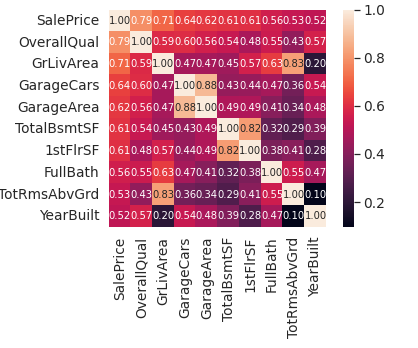
OverallQual、GrLivArea,TotalBsmtSFは、SalePriceと強い相関があります。
また、GarageCarsとGarageAreaも強い相関を持ちます。
しかし、車庫に入る車の台数は車庫面積の結果です。
そのため、GarageAreaではなく、SalePriceとの相関がより強いGarageCarsを使用するとよいでしょう。
最後に、それらの次に相関が高いのがFullBath,YearBuiltです。
SalePriceと強い相関があるOverallQual、GrLivArea,TotalBsmtSF、GarageCars、FullBath, YearBuiltも加え、これをもとに散布図をみてみましょう。
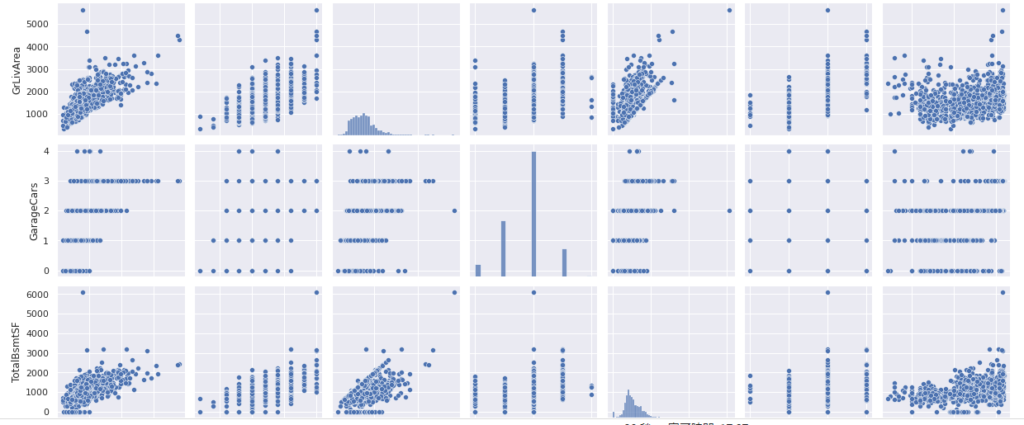
最後に、欠損値とその割合をみてみます。
from pandas.core import missing
total = df_train.isnull().sum().sort_values(ascending=False)
percent = (df_train.isnull().sum()/df_train.isnull().count()*100).sort_values(ascending=False)
missing_data = pd.concat([total,percent],axis=1,keys=['Total','Percent'])
missing_data.head(20)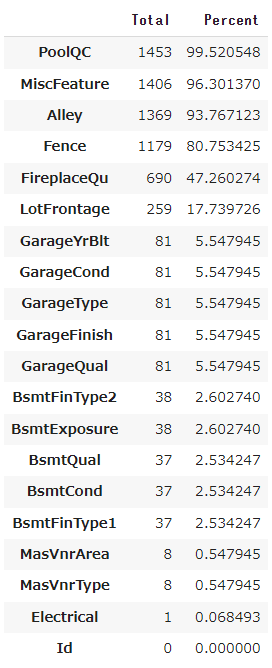
Kaggleで悩んだら
「Kaggle で勝つデータ分析の技術」
以下の書籍は、Kaggleを始める方には本当にオススメの書籍です。Kaggleでわからないことや悩んだことがあった方は、購入を検討してみください。
本だけでは物足りないという方は、動画のプラットフォームで学ぶこともオススメです。興味がございましたら、以下の無料のオンライン説明会に参加してみてはいかがでしょうか。

