








はじめにーEDAとは
データ分析の業務に携わるときに必ず行う作業があります。
それが、EDA(Exploratory Data Analysis)です。
これは、データ分析の最初のステップであり、取り扱っているデータの中身を理解するための作業です。以下に、EDAの主なアプローチと手法をいくつか説明します。
1.データの概要を確認する:データセットのサイズを確認し、カラム(特徴)の数と種類を把握します。データの最初のいくつかの行やサンプルを表示して、データのフォーマットや値の範囲を理解します。
2.データの欠損値を処理する:欠損値の有無を確認し、欠損値を適切に処理します。欠損値は、分析やモデリングに影響を及ぼす可能性があるため、適切に対処する必要があります。
3.データの要約統計を計算する:データの統計的な要約を計算し、平均、中央値、標準偏差、最小値、最大値などの情報を把握します。これにより、データの分布や外れ値の有無を把握できます。
4.データの可視化:ヒストグラム、散布図、箱ひげ図、バブルチャートなどのグラフを使用して、データの分布や相関関係を可視化します。視覚的な表現により、データの特徴やパターンがより明確になります。
5.特徴間の相関を調査する:特徴間の相関関係を確認し、データの中でどの特徴が重要かを理解します。相関は、特徴選択や特徴エンジニアリングの指針として役立ちます。
実際のデータを用いて欠損値を調査
今回使用するデータは、KaggleのHouse Prices – Advanced Regression Techniquesのデータを用いてみます。
KaggleのHouse Pricesについて詳しく知りたい方は以下のブログを記事をご覧ください。
>>【Kaggle入門ー重回帰分析】 Titanicの次に何をやるか!? House Prices – Advanced Regression Techniques
まずは、どんなデータなのか見てみます。

各住宅の販売価格を予測するための学習データですので、建物のクラスや建築素材、部屋の大きさ等価格に影響を与える変数が並んでいます。
info()
多くのカラムがあるので、途中省略されています。これについての要約をみてみましょう。その際には、info()を使うことで、データ数、カラム名と数、データがある行数(その反対として欠損値の数もここから推測できる)、データ型を簡単に表示できます。
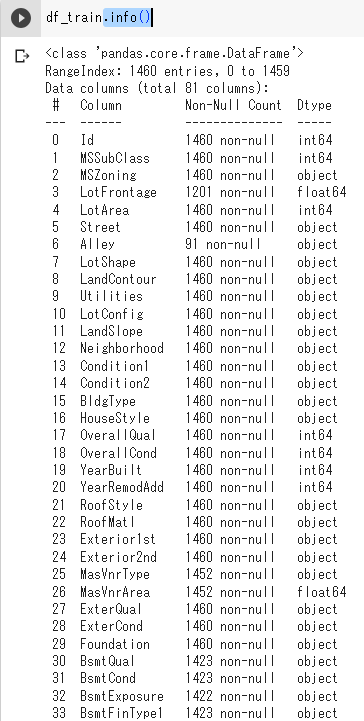
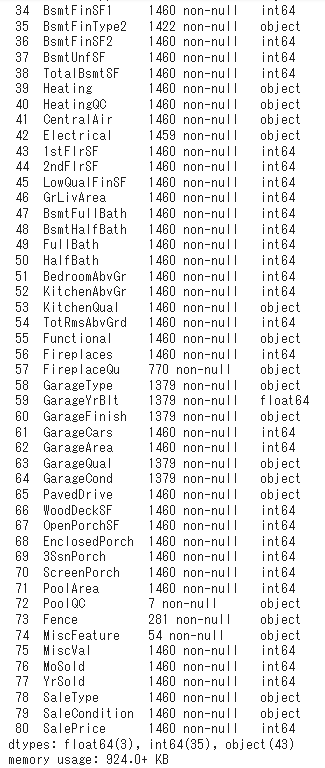
具体的にいうと、ここからわかることは、データ数(0~1459のインデックスがあるので、1460個のデータ)、カラム数は81、カラム名は表示されているとおり。各カラムにつき、データ数(non-nullとあるので、データが欠損(Null)していない数という意味です。)とデータの型(intかobjectか)が表示されています。
isnull().sum()
要約からみて、欠損値があることがわかりましたので、表示してみましょう。
その際に使うのが、isnull().sum()です。isnull()だけだと、ブール値で欠損値の有無(True:欠損値、False:データあり)が表示されます。これをsum()を用いることで合計値を計算できます。
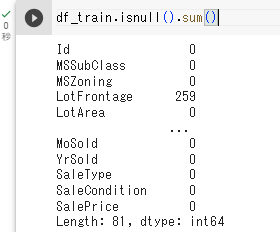
しかし、今回のデータはカラムが81個もあるので、このままでは、全部表示されません。そこで、すべてのカラムを表示するように設定を変更する必要があります。
pd.set_option(‘display.max_rows’,100)をしましょう。これをすることで、100行まで表示できるように変更されます。

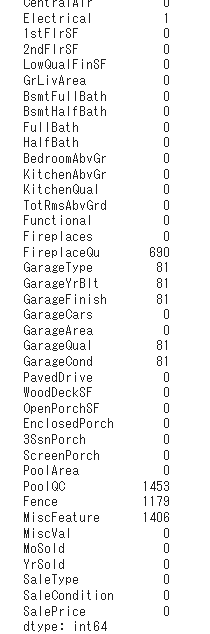
81個もあるとスクロールしないと欠損値を把握できませんし、単純にこれだと見ずらいです。ここで欠損値を多い順に変更して見やすくしてみましょう。.sort_values(ascending=False)を用いれば、順番を降順に変更できます。
df_train.isnull().sum().sort_values(ascending=False)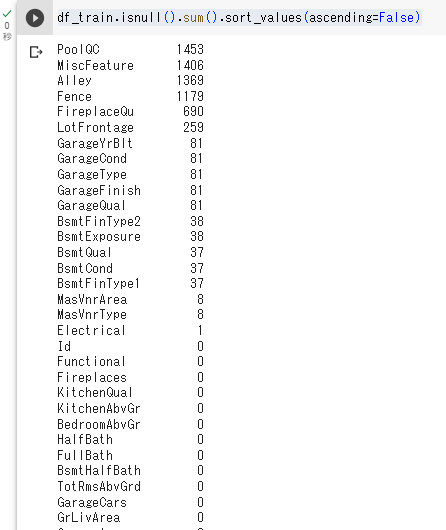
これですごく見やすくなりました!!
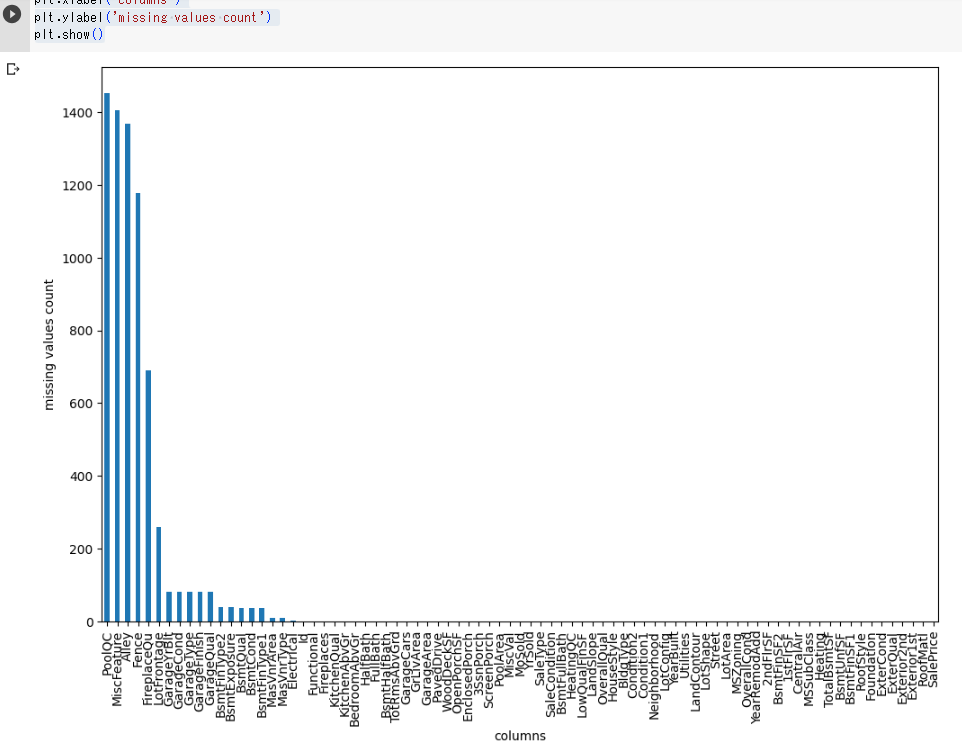
最後に、これをplotして視覚的にわかりやすくしてみましょう。
missing_values = df_train.isnull().sum().sort_values(ascending=False)
plt.figure(figsize=(12,8))
missing_values.plot(kind='bar')
plt.xlabel('columns')
plt.ylabel('missing values count')
plt.show()欠損値の降順をmissing_valuesに格納します。
サイズは今回は横12、縦8にとりあえず設定します(図が見ずらい場合は、こちらを再度変更します。)
これをbarチャート(棒グラフ)で表示します。
x軸名としてカラム、y軸名として欠損値の数とします。
これを表示すると以下のようになります。
Missingno
今回は、isnull().sum()を用いましたが、Missingnoを用いる方法もあります。
これを用いることで、データの割合とデータ数が表示できます。
import missingnoimportできない場合は、pip install missingno でインストールしてください。
missingno.bar(df_train)
こちらの図の見方ですが、図の一番上の0.0~1.0がデータの割合です。
例えば、SalePriceでみると1.0なので、右側に表示されているようにデータが1460個(つまり、欠損値なし)です。
一方、MiscFeature~PoolQCあたりがデータの割合が小さいので、欠損値が多そうです。
まとめ
欠損値は、分析やモデリングに影響を及ぼす可能性があるため、適切に対処する必要があります。
そのため、実務では、EDA(Exploratory Data Analysis)の最初のステップとして、欠損値を調査することが行われています。
参考になれば幸いです。

