









はじめに
昨年、社内で生成AIを「試してみた」。でも——
- 何がどれだけ良くなったのか、説明しづらい
- 部署ごとに使い方がバラバラで、再現性がない
- リスクが気になって、結局“無難な用途”しか回っていない
このような悩みに多くの企業が陥っています。
原因はシンプルで、「最初にどの業務から入るか」を“インパクト(効果)×リスク”で決めていないことが多いからです。
この記事では、導入初期に選ぶべき業務を機械的に決める手順に落とす方法を紹介します。
簡易な業務選定基準
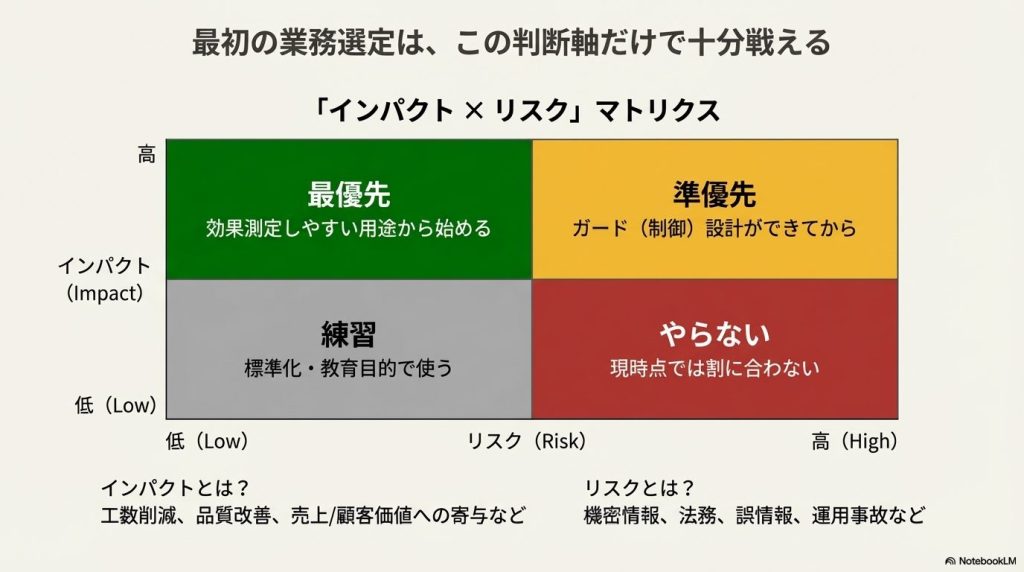
簡易な業務選定としては 「インパクト×リスク」 で十分選定できます。
インパクトは「時間削減・品質改善・売上/顧客価値への寄与」など。
リスクは「機密・法務・誤情報・運用事故」など。
これを会社の業務当てはめてみて、判断するのが一番簡易な方法です。
より実践的な方法
ここでは、「総務部が、福利厚生などの社内ドキュメントを元にチャットボットを作り、社員が利用する」という架空ケースで、導入判断に必要な材料を提示します。
ポイントは、インパクト=何がどれだけ良くなるか、リスク=何がどう困るかを、同じ粒度で並べることです。
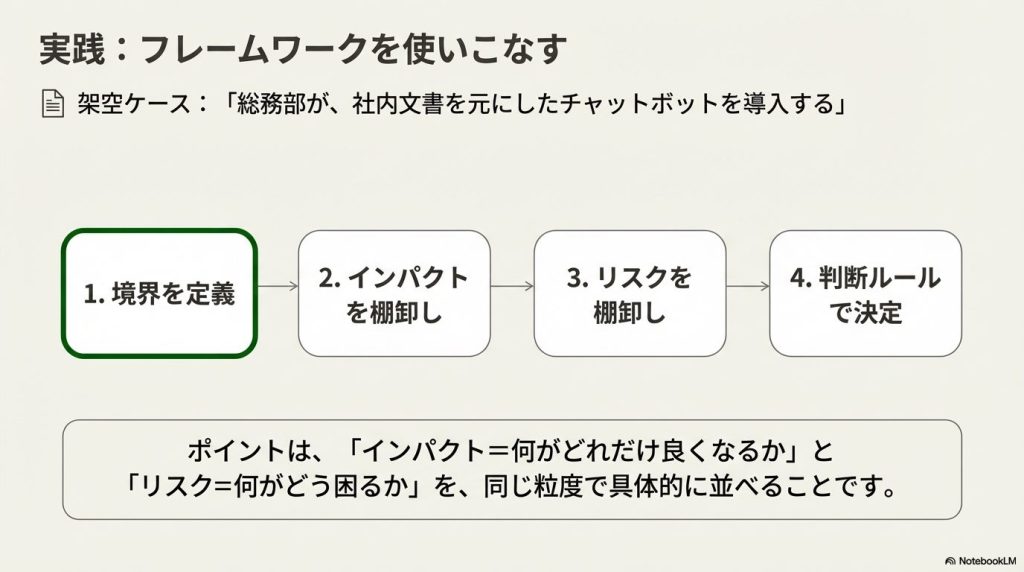
1) まず「ユースケースの境界」を1分で定義する(前提カード)
前提を整理します。
- 対象:福利厚生・社内手続き・申請方法など(例:FAQがある領域)
- 利用者:社員(数十〜数千などレンジで想定)
- 出力の扱い:社内向け案内(対外ではない)
- 仕組み:RAG(社内文書検索+生成の仕組み)で回答
- 運用:まずは“案内の一次回答”まで(申請の自動実行などはしない)
2) インパクトを「4カテゴリ」で棚卸しする
インパクトは、部門の成果に落ちる形に分けると迷いません。
| インパクト観点 | 何が改善するか(例) | 測り方の例(レンジでOK) |
| 工数削減 | 問い合わせ対応の一次回答を自動化/半自動化 | 対応件数(数十〜数百/月)× 1件あたり時間(数分〜数十分) |
| 回答品質の平準化 | 担当者で回答がブレる、言い回しが違うのを減らす | 手戻り(数件〜数十/月)や訂正対応の減少 |
| 従業員体験(EX) | 「どこに書いてある?」探し時間の削減 | 検索時間の短縮、自己解決率の上昇(体感でも可) |
| ナレッジ整備促進 | FAQ/規程の穴が見つかる(文書が整う) | 文書の更新件数(数件〜数十/月) |
コツ:ここでは“精密な数値”より、測れる形にしておくということが大事です。
3) リスクを「4カテゴリ」で棚卸しする
リスクは「漏えい」だけにすると判断を誤ります。総務チャットボットなら、この4つで十分に実務的です。
| リスク観点 | 何が起きうるか(例) | 低減の方向性(設計で潰す) |
| 情報の不適切露出 | 本来見せない情報が回答に混ざる | 文書の公開範囲を分離、アクセス制御、回答根拠の限定 |
| 誤回答(ハルシネーション) | 規程と違う案内、古い情報で回答 | 根拠提示、最新版のみ参照、曖昧時は「人へ誘導」 |
| 規程改定への追従遅れ | 文書更新が反映されず混乱 | 更新フロー(誰がいつ反映)を決める |
| 依存・過信 | ボット回答を“確定”と誤解する | 注意書き、最終判断の導線(窓口/規程リンク) |
コツ:リスクは起きた時の影響×起きやすさで見ると判断が速いです。
4) 判断基準の設定
インパクトとリスクを棚卸ししたら、次は「どういう条件ならGoできるか」の判断基準を設定します。この判断基準は自社で詳細に検討する必要があるかと思いますが、仮として以下で設定します。
✅ Go(開始OK)
次の2つを 両方 満たす場合にGo。
- インパクト側の合格条件
- インパクト「中以上」が 2項目以上(工数/品質/EX/ナレッジのうち)
- かつ、インパクトが 測定可能な形(件数×時間、手戻り、更新数など)で説明できる
- リスク側の合格条件
- 「高」になっているリスクがあってもよいが、設計・運用の対策で“制御可能”
- 少なくとも次の“致命傷”のリスクが残っていない
- 情報の不適切露出が 制御できない(公開範囲の分離やアクセス制御ができない等)
- 誤回答が起きたときに 検知・抑制・是正の導線がない(根拠提示、人への誘導などが入らない)
- 情報の不適切露出が 制御できない(公開範囲の分離やアクセス制御ができない等)
⚠ 条件付きGo(条件を満たしたら開始)
次に当てはまる場合は、”条件が揃ったらGo”にして前に進めます。
- インパクトは高い(または中以上が多い)が、測定設計がまだ粗い
- リスクが「中〜高」で、対策は見えているが 実装/運用フローが未確定
例:アクセス制御の方式、根拠提示の形式、更新責任者の割当などが未決
❌ No-Go(今はやらない)
対策のコストや運用負荷が重く、インパクトと釣り合わないからNo-Go。
実際にGOする前に準備しておくこと
次にやるべきは、測れる形で回る“運用の最小セット”を作ることです。
多くの場合、ここを雑にすると「便利だった気がする」で終わります。
Step 1:条件付きGoの“未充足条件”を、作業タスクに変換する
第2ブロックの未充足条件(Yes/No)を、そのまま作業に落とします。ここは3つまでに絞るのがコツです。
- A:公開範囲の分離・アクセス制御(不適切露出対策)
- 参照文書を「見せて良い範囲」で分ける(例:全社員OK/限定公開など)
- チャットボットが参照できる範囲を固定する(“混ざらない”状態にする)
- 参照文書を「見せて良い範囲」で分ける(例:全社員OK/限定公開など)
- B:根拠提示を標準にする(誤回答対策)
- 回答は「結論+根拠(参照元)」の型に固定する
- 根拠が出せない場合の挙動を固定する(例:窓口へ誘導)
- 回答は「結論+根拠(参照元)」の型に固定する
- C:更新フローを決める(規程改定の追従)
- “誰が・いつ・何を更新したら、どこに反映されるか”を決める
- 反映漏れを検知する簡易ルールを置く(例:更新時にチェック)
- “誰が・いつ・何を更新したら、どこに反映されるか”を決める
ここで大事なのは「頑張って運用」ではなく、運用が勝手に回る形(責任と手順)に固定することです。
Step 2:測定設計を“導入前”に固定する
測定は難しくしない方がうまくいきます。レンジでOKなので、導入前に最低限のベースラインを検討しておきます。
- 何を測るか(3〜4個に絞る)
- 問い合わせ対応の総量:件数(数十〜数百/月)
- 対応コスト:1件あたり所要時間(数分〜数十分)
- 品質の手戻り:訂正・追加対応(数件〜数十/月)
- ナレッジ整備:FAQ/規程の修正・追加(数件〜数十/月)
- 問い合わせ対応の総量:件数(数十〜数百/月)
- どう取るか(簡易でOK)
- 期間:数週間〜1か月
- サンプル:数十件程度から
- 記録:担当者が“ざっくりでも残せる”形(細かさより継続性)
- 期間:数週間〜1か月
Step 3:運用ルールを決める
ここは文章で固定します。ポイントは、人の判断が必要な場面を先に定義すること。
- 回答は必ず根拠を添える(参照元の提示)
- 根拠が出せない/曖昧な場合は窓口へ誘導する
- 参照する文書範囲は固定(勝手に広げない)
- 規程改定があったら更新フローに従って反映する
- 利用者が誤回答を見つけたときの連絡導線を用意する(是正の入口)
よくある落とし穴:
ルールを決めずに走り出し、「誰が責任を持つのか」が曖昧なまま運用が崩れる。
Step 4:小さく回して“改善の回転”を作る(最初から完成を目指さない)
最初の目的は「完璧な回答」ではなく、改善が回る状態です。
- 誤回答・誘導・参照不足などを分類して、改善の優先順位を付ける
- 改善は「文書を直す」「FAQを足す」「誘導文を直す」など、運用で回せるものから
- リスクが上がる拡張(範囲拡大・自動化)は、再度マトリクスで評価してから
カですら「利便性」のみでは必ずしも浸透しないので、生成AIの社内利活用を進める際には、ブレーキとして存在しているものを見極め、それを取り除く作業が必要になります。
架空ケース3例


まとめ
- 生成AI導入で最初にやるべき業務は、「やれそう」ではなく インパクト×リスクで機械的に選ぶ。
- Goサインは「リスクがゼロ」だから出すのではなく、効果が測れる見通しと致命傷(制御不能な露出/是正導線なし)が塞がっていることで出す。
- Go後に重要なのは測れる運用(未充足条件をタスク化/ベースライン取得/運用ルール固定)を先に作ること。
- 高インパクト領域ほど、最初は “下書き・支援”止まりで始め、条件が揃ってから拡張するのが安全で速い。
このような方法を用いれば、生成AIによる効果を測ることが可能な導入へと進めることができます!
生成AIについてもっと学んでみたいという人向けにオススメ書籍9選を紹介しています!
↓興味がある方は是非ご覧ください↓
>>【厳選9書籍】生成AIの勉強に最適!初心者〜実務レベルまで本音でおすすめできる書籍まとめ