









論文『Attention Is All You Need』概要
『Attention Is All You Need』は、2017年に発表された自然言語処理分野における画期的な論文です。この論文では、従来のSequence-to-Sequenceモデルでよく用いられていたRNN(Recurrent Neural Network、リカレントニューラルネットワーク)やCNN(Convolutional Neural Network、畳み込みニューラルネットワーク)を排除し、Self-Attention(自己注意機構)のみを用いた新しいニューラルネットワークアーキテクチャTransformerを提案しました。
<Transformerの構造>
Transformerアーキテクチャ: モデルはエンコーダとデコーダで構成されています。エンコーダは、Multi-Head Attention(複数の自己注意機構)で構成され、デコーダはMulti-Head Attention(複数の自己注意機構)とEncoder-Decoder Attention(もしくはSource Target-Attention)で構成されます。
Self-Attention(自己注意機構): このメカニズムは、入力文内の単語間または出力文内の単語間の関連度を計算します。この計算にはsoftmax関数が使われます。各単語がどの程度重要か(注意するべきか)を決定するための確率を計算します。各計算は独立して行うことができるため、すべての計算を並列に行え、高速化を可能にします。
Multi-Head Attention:Transformerでは、複数の自己注意機構を並行して使用します。これにより、モデルは異なる位置や特徴に焦点を合わせることができます。各自己注意機構は独自の重みを学習し、異なる視点で情報を捉えることができるため、より豊かな表現を作り出すことができます。
Encoder-Decoder Attention:デコーダが出力を生成する際に、入力文の情報も利用します。このメカニズムは、デコーダが生成する各単語が、エンコーダによって処理された入力文のどの単語に関連しているかを学習します。
Positional Encoding(位置エンコーディング): Transformerはリカレントや畳み込みを使用しないため、モデルにシーケンスの順序に関する情報を与えるために位置エンコーディングを使用します。
<Transformerの利点と性能>
並列化の効率: RNNとは異なり、Transformerはシーケンス全体を一度に処理できるため、トレーニングが高速です。これは、すべての単語が同時に処理されるため、GPUなどの並列計算が効率的に利用できるからです。
長距離依存関係の学習: 自己注意機構は、シーケンス内の任意の距離にある単語間の関係を直接モデル化できるため、長距離依存関係の学習が容易です。RNNやCNNでは、長距離の依存関係を学習するために多くの層が必要でしたが、Transformerではこれが直接可能です。
性能:英語からフランス語への翻訳タスクで、以前の最先端モデルよりも高い精度を達成しました。また、トレーニング時間も短縮されており、モデルのサイズと性能のバランスが良好です。
という感じですと、いまいちよくわかりませんよね。
そこで、中学生でも理解できるように以下に、まとめました!
中学生でも理解できる『Attention Is All You Need』
1. エンコーダとデコーダ
Transformerには、「エンコーダ」と「デコーダ」という2つの部分があります。それぞれの役割を簡単に説明します。
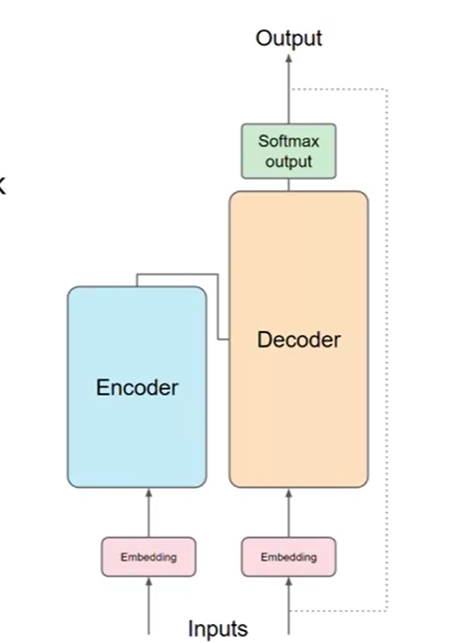
- エンコーダ: これは、入力された文章を理解する役割を持っています。エンコーダは文章の中の単語がどう関係しているかを学びます。例えば、「私はリンゴを食べました」という文を見たときに、「私は」という主語と「食べました」という動詞がつながっていることを理解します。
- デコーダ: これはエンコーダの理解をもとに、新しい文章を作り出す部分です。例えば、翻訳タスクの場合、デコーダは「私はリンゴを食べました」を英語にして「I ate an apple」という文章を作ります。
2. Self-Attention(自己注意機構)について
Self-Attention(自己注意機構)は、Transformerの中心的な部分です。この仕組みがなぜ重要なのかをもう少し掘り下げて説明します。
- 全体を見渡す力: 自己注意は、文章の全体を一度に見ることができるので、文章中のどの単語が他の単語と関係しているのかを把握しやすいです。例えば、「図書館で本を借りたが、後でカフェでそれを読んだ」という文では、「それ」という単語が「本」を指していることを認識するのが自己注意の役割です。
- 複数の視点で見る: Transformerは一度に複数の自己注意を使います。これをMulti-Head Attentionと言います。これにより、文章の中で同時にいくつもの視点から重要な情報を見つけ出すことができます。たとえば、「時間」「場所」「動作」など、異なる観点で文章を理解します。
3. Positional Encoding(位置エンコーディング)の役割
Positional Encoding(位置エンコーディング)は、Transformerが単語の順序を覚えるために使う目印のようなものです。Transformerは文章全体を一度に見るので、どの単語がどの位置にあるのかがわからなくなってしまうことがあります。そこで、位置エンコーディングを使って、「これは文章の最初の単語」「これは真ん中の単語」など、単語の場所を覚えます。
4. Encoder-Decoder Attentionの役割
Encoder-Decoder Attentionは、デコーダが新しい文章を作るときに、エンコーダがどの情報を重要だと考えたかを利用する仕組みです。具体的に言うと、デコーダが次の単語を決めるときに、エンコーダが入力された文章のどの部分に注目したかを確認して、その情報をもとに正しい単語を選びます。
5. Transformerのメリット
- 効率的な学習: Transformerはリカレントニューラルネットワーク(RNN)と違って、すべての単語を一度に処理できるので、学習が速いです。これは、例えば、学校のプロジェクトでみんなが同時に作業するように、時間を短縮できます。
- 長い文章も扱える: RNNや従来の方法だと、長い文章を理解するのは大変でした。前の情報をどんどん覚えなければならなかったからです。でも、Transformerは全体を見ることができるので、長い文章でもスムーズに理解できます。
- 翻訳の精度が高い: 例えば、英語を日本語に翻訳するとき、Transformerは従来の方法よりも正確に翻訳できることが多いです。なぜなら、文章全体の意味や単語同士の関係をより正確に理解できるからです。
まとめ
Transformerは、文章を理解して処理するための新しい方法です。従来の方法よりも速くて賢いのが特徴です。文章を理解するときに、Self-Attention(自己注意機構)という仕組みを使って、文章の中で重要な単語に注目します。そして、今では多くのAI技術の基盤となっています!
ChatGPTの技術について知りたい方は以下のブログ記事をご覧ください。
>>【ビジネスマン必見!】これだけ知ってたら大丈夫~ChatGPTの技術
