








はじめに
Kaggleは、英語のページしかありません。そこで、日本語で読みたい方向けに記事を作成しました。
Santander Customer Transaction Predictionの概要の説明が前の記事で済みました。
実際にGoogle Colabを動かしてみましょう!
Google Colaboratoryについては知りたい方は、以下のブログ記事を参考にしてください。
>>Google Colaboratoryとは? いつできた? mount、ファイルの読み込み等の使い方
>>Google Colaboratoryよく使う便利なショートカットキー
データのインポート
ドライブをマウントしてください。
from google.colab import drive
drive.mount('/content/drive')必要なものをインポートします。
import datetime
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn.model_selection import StratifiedKFoldそして、データをインポートします。
train_df = pd.read_csv('/content/drive/MyDrive/kaggle/Santander/train.csv')
test_df = pd.read_csv ('/content/drive/MyDrive/kaggle/Santander/test.csv')注意:‘/kaggle/Santander/train.csv’←の部分はドライブのフォルダ構成によって内容が異なるので注意してください。
train_df.shape, test_df.shape


データは非正規化されており、各行には数字だけで識別された200個の数値(var_0~var_199)が含まれています。
データの確認
データの欠落とデータの種類を確認します。
missing_dataという関数を作成します。
def missing_data(data):
total = data.isnull().sum()
percent = (data.isnull().sum()/data.isnull().count()*100)
tt = pd.concat([total,percent],axis=1,keys=['Total','Percent'])
types = []
for col in data.columns:
dtype = str(data[col].dtype)
types.append(dtype)
tt['Types'] = types
return(np.transpose(tt))missing_data(train_df)
データの欠落はありません。
また、データの種類は、ID_codeがobject型、targetがint64型、var_はfloat64型です。
EDA
データの統計量をみてみましょう。
train_df.describe()
test_df.describe()
散布図で確認します。
def plot_feature_scatter(df1,df2,features):
i = 0
sns.set_style('darkgrid')
plt.figure()
fig,ax = plt.subplots(4,4,figsize=(14,14))
for feature in features:
i += 1
plt.subplot(4,4,i)
plt.scatter(df1[feature],df2[feature],marker='+')
plt.xlabel(feature,fontsize=9)
plt.show();データの5%(var_0~var_15)だけ、散布図を表示します。
features = ['var_0', 'var_1','var_2','var_3', 'var_4', 'var_5', 'var_6', 'var_7',
'var_8', 'var_9', 'var_10','var_11','var_12', 'var_13', 'var_14', 'var_15',
]
plot_feature_scatter(train_df[::20],test_df[::20], features)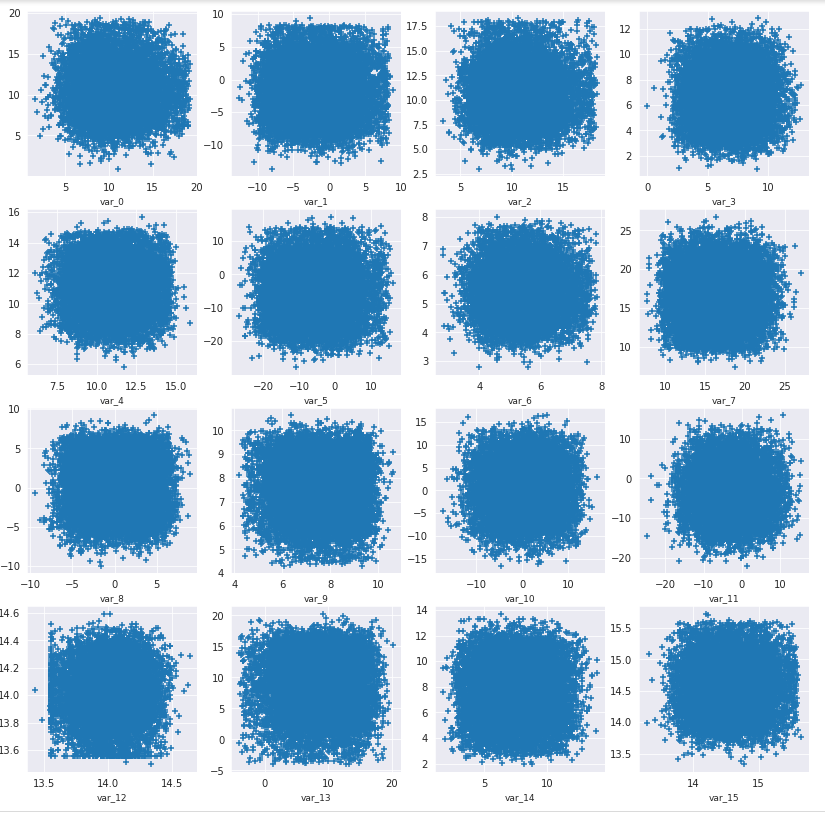
‘target’を0と1の総数を確認します。
sns.countplot(train_df['target'],palette='Set3')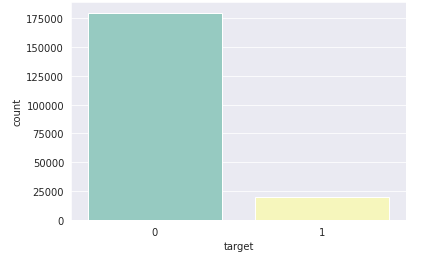
データの変数の密度を示す関数を作成します。
def plot_feature_distribution(df1, df2, label1, label2, features):
i = 0
sns.set_style('whitegrid')
plt.figure()
fig, ax = plt.subplots(10,10,figsize=(18,22))
for feature in features:
i += 1
plt.subplot(10,10,i)
sns.distplot(df1[feature], hist=False,label=label1)
sns.distplot(df2[feature], hist=False,label=label2)
plt.xlabel(feature, fontsize=9)
locs, labels = plt.xticks()
plt.tick_params(axis='x', which='major', labelsize=6, pad=-6)
plt.tick_params(axis='y', which='major', labelsize=6)
plt.show();最初の100個(var_0~var_99)を表示します。
t0 = train_df.loc[train_df['target']==0]
t1 = train_df.loc[train_df['target']==1]
features = train_df.columns.values[2:102]
plot_feature_distribution(t0,t1,'0','1',features)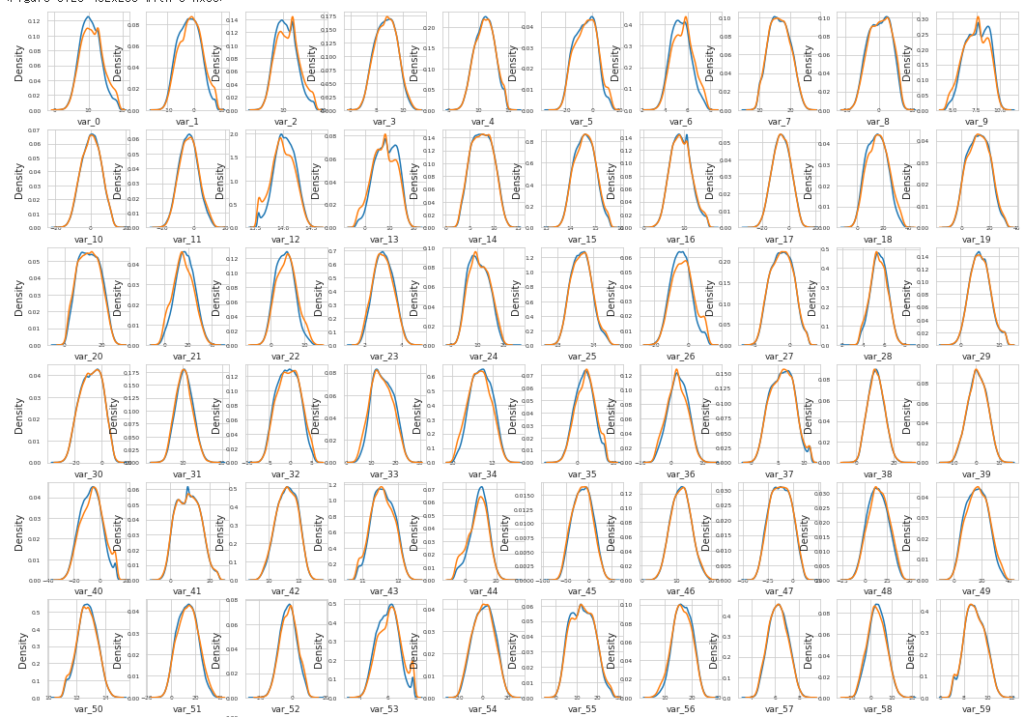
次の100個(var_100~var_199)を表示します。
features = train_df.columns.values[102:202]
plot_feature_distribution(t0, t1, '0', '1', features)
2つの目標値(targetの0,1)に対して、著しく分布が異なる特徴量が相当数存在することがわかる。
例えば、var_0, var_1, var_2, var_5, var_9, var_13, var_106, var_109, var_139などである。
特徴量の作成
trainデータのカラムから、ID_codeとtargetを落として、特徴量とする。
features = [c for c in train_df.columns if c not in ['ID_code', 'target']]
target = train_df['target']モデルの作成と実行
param = {
'bagging_freq': 5,
'bagging_fraction': 0.4,
'boost_from_average':'false',
'boost': 'gbdt',
'feature_fraction': 0.05,
'learning_rate': 0.01,
'max_depth': -1,
'metric':'auc',
'min_data_in_leaf': 80,
'min_sum_hessian_in_leaf': 10.0,
'num_leaves': 13,
'num_threads': 8,
'tree_learner': 'serial',
'objective': 'binary',
'verbosity': 1
}folds = StratifiedKFold(n_splits=10, shuffle=True, random_state=44000)
oof = np.zeros(len(train_df))
predictions = np.zeros(len(test_df))
feature_importance_df = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_df.values, target.values)):
print("Fold {}".format(fold_))
trn_data = lgb.Dataset(train_df.iloc[trn_idx][features], label=target.iloc[trn_idx])
val_data = lgb.Dataset(train_df.iloc[val_idx][features], label=target.iloc[val_idx])
num_round = 1000000
clf = lgb.train(param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=1000, early_stopping_rounds = 3000)
oof[val_idx] = clf.predict(train_df.iloc[val_idx][features], num_iteration=clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = features
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
predictions += clf.predict(test_df[features], num_iteration=clf.best_iteration) / folds.n_splits
print("CV score: {:<8.5f}".format(roc_auc_score(target, oof)))特徴量の重要性をみてみます。
cols = (feature_importance_df[["Feature", "importance"]]
.groupby("Feature")
.mean()
.sort_values(by="importance", ascending=False)[:150].index)
best_features = feature_importance_df.loc[feature_importance_df.Feature.isin(cols)]
plt.figure(figsize=(14,28))
sns.barplot(x="importance", y="Feature", data=best_features.sort_values(by="importance",ascending=False))
plt.title('Features importance (averaged/folds)')
plt.tight_layout()
plt.savefig('FI.png')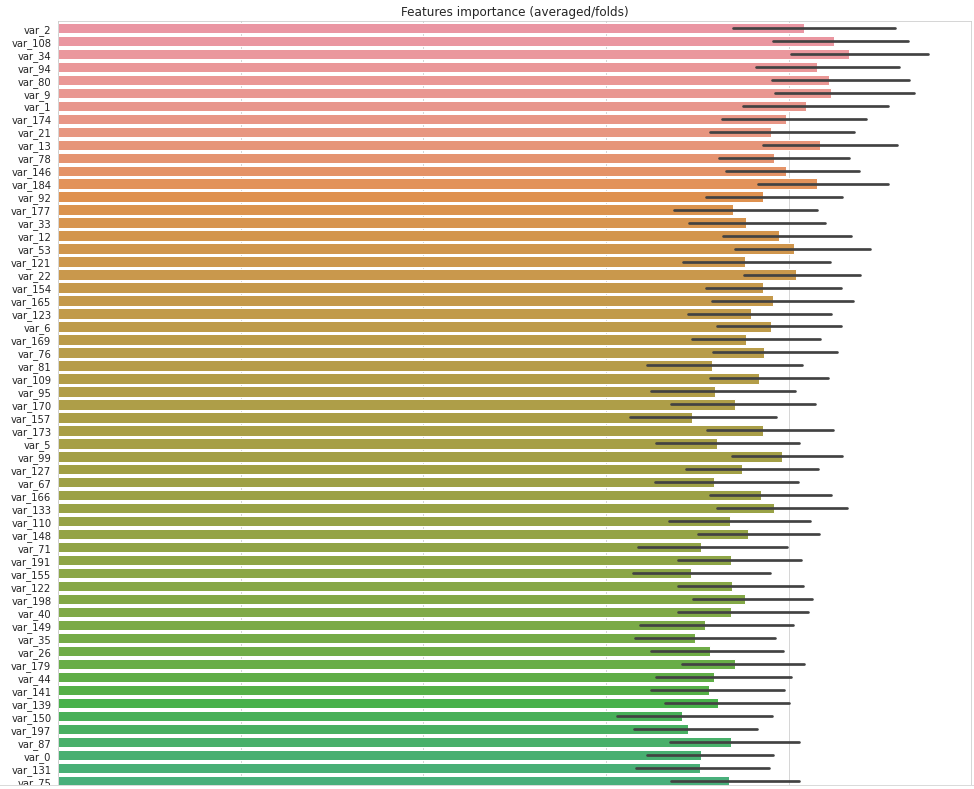
ファイルの提出
sub_df = pd.DataFrame({'ID_code':test_df['ID_code'].values})
sub_df['target'] = predictions
sub_df.to_csv('submission.csv',index=False)Kaggleで悩んだら
「Kaggle で勝つデータ分析の技術」
以下の書籍は、Kaggleを始める方には本当にオススメの書籍です。Kaggleでわからないことや悩んだことがあった方は、購入を検討してみください。
本だけでは物足りないという方は、動画のプラットフォームで学ぶこともオススメです。興味がございましたら、以下の無料のオンライン説明会に参加してみてはいかがでしょうか。

